AI Governance
AI Governance
by
Jean S. Bozman, President,
Cloud Architects Advisors LLC
and
M. R. Pamidi, Ph.D.,
Cabot Partners
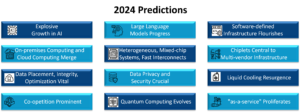
AI and GenAI are still “center-stage” for many companies, large and small, in the wake of a global wave of rapid adoption for GenAI software that accelerated in 2023. Chatbots and large language models (LLMs) soared in popularity in 2023 following the release of GenAI products, including OpenAI’s ChatGPT, Google’s Bard, and Microsoft’s Copilot chatbot, among others.
Business leaders worldwide are envisioning how they will apply AI to solving business challenges. They are deploying AI-enabled business solutions in retail, manufacturing, health care, and many other industry sectors. However, securing and managing AI across business units in large enterprises are critical challenges they must address. In the wake of recent AI deployments, improved security can be an after-thought – or an add-on for some customers.
Now, AI-enabled silos must be monitored and managed as part of a company-wide tracking ability designed to manage applications securely and consistently across hybrid clouds and multi-clouds.
Proliferation, then Consistency Across the Organization
Building a consistent approach to AI deployments is a “must” for businesses to ensure that policies and security guardrails (standards and best practices) are in place applying them throughout a business organization. This approach will allow later audits for end-to-end data integrity, consistency, and management.
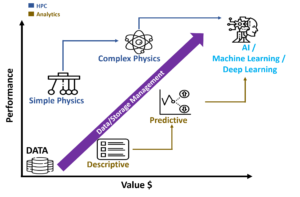
AI governance is not a one-size-fits-all solution. Instead, it is a context-specific and dynamic process that requires continuous monitoring and evaluation. In a governance model, all the managed AI systems should be viewable by IT’s central management dashboards. Ideally, the end users should involve a diverse and inclusive range of stakeholders, reaching AI systems accessed by developers, ethicists, policymakers, and business end users to ensure that a broad range of perspectives and interests are considered and balanced.
There is much homework to do before deploying AI governance. As a matter of design, AI governance should also cover the entire AI lifecycle – spanning the following elements: data collection and processing, model development and testing, deployment and maintenance, and, ultimately, the decommissioning of specified AI systems at their end of life (EOL).
Some of the key components of AI governance are:
- Data governance: The management of data quality, security, privacy, and ethics to ensure that the data used to train and test AI models are accurate, reliable, representative, and respectful of human rights.
- Ethical governance: The administration of ethical principles, values, and norms to ensure that the AI systems align with the moral and social expectations of the stakeholders and society at large.
- Model governance: The management of model performance, robustness, fairness, and explainability to ensure that the AI models produce valid, reliable, unbiased, and interpretable results and decisions.
- Operational governance: The tracking of operational risks, compliance, and auditability to ensure that the AI systems are deployed and used in a safe, secure, and lawful manner – and that their impacts and outcomes are monitored and evaluated.
The Whys of AI Governance
As noted above, securing and managing AI across business units in large enterprises are essential challenges when business applications and data leverage AI. Enterprise-wide AI governance helps organizations effectively to do the following:
- Comply with existing and emerging regulations and standards that apply to AI, such as the EU’s General Data Protection Regulation (GDPR), the California Privacy Rights Act (CCPA), and the Artificial Intelligence Research, Innovation, and Accountability Act of 2023 (AIRIA) introduced by the U.S. Senate in November 2023.
- Build trust and confidence among a range of stakeholders, such as customers, employees, partners, and regulators, by demonstrating transparency, “explainability” regarding data sources, lack of bias, and, ultimately, accountability for their AI systems.
- Achieve their strategic goals and objectives by ensuring their AI systems align with an organization’s values, corporate mission, and strategic vision.
Building a consistent approach to AI deployments is a “must” for businesses that must ensure that policies and security guardrails are in place, applying them throughout a business organization.
IBM and Enterprise AI
As announced at IBM’s THINK conference in April 2023, IBM is taking an enterprise-wide approach to AI governance. IBM released its watsonx.ai development toolkit and data-monitoring software, watsonx.data, in Spring 2023. In December, IBM released its watsonx.governance software into general availability (GA) – making it a new product released and made available to customers in 2024.
Many readers will recall the IBM Watson AI software portfolio released in 2013. The new watsonx portfolio targets today’s business and IT environments, including new functionality for AI, hybrid cloud, and multi-cloud deployments. They should note that the new watsonx software portfolio, as announced last spring, has three deliverables:
- IBM watsonx.ai enterprise studio platform for software developers;
- IBM watsonx.data, which catalogs enterprise data in data warehouses, data lake-houses, and corporate data stores;
- IBM watsonx.governance software to monitor and manage AI across the enterprise.
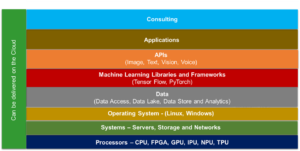
The release of watsonx.governance software supports an enterprise-wide view of AI activity and use cases – and a view of how their data center and cloud resources support the AI systems within the enterprise. This capability will help businesses to “scale up” their AI infrastructure consistently across the enterprise.
The December release has expanded capabilities for viewing LLM development, monitoring LLM metrics, and managing the lifecycle of LLMs throughout the software lifecycle. The software tools help avoid bias and data inaccuracies and prevent AI “drift” as the LLMs operate over months and years. IBM said it plans to expand its governance software to add support for third-party AI models from other vendors, starting in Q1 2024.
Kareem Yusuf, Ph.D., Senior Vice President, Product Management and Growth, IBM Software, described IBM watsonx.governance as a unified solution for businesses deploying and managing LLM and ML models. Governance software provides tools for increased visibility, providing software to “automate AI governance processes, monitor their models, and take corrective action.” Quoted in an IBM press release, Yusuf summed up the business value of customers’ governance-software deployments. “Company boards and CEOs are looking to reap the rewards from today’s more powerful AI models, but the risks due to a lack of transparency and inability to govern these models have been holding them back,” he said.
Analyst Outlook for 2024
Across all industries and sectors, AI and GenAI are gaining attention and adoption in 2024 as customers think about how they will coordinate and secure AI deployment throughout their organizations.
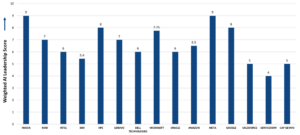
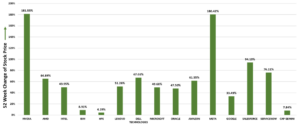
Undoubtedly, AI is gaining traction to automate business processes and identify those processes that create bottlenecks or delays in supply chains that affect end customers. We note here that IBM is not alone in offering a governance model for AI. Competitors offering AI governance tools, and not just advisory and consulting services, include Amazon SageMaker, Credo AI, Dataiku DSS, MLOps platform, Google Vertex AI, Holistic AI, Microsoft AI Content Safety, and Microsoft Azure Machine Learning, Minitaur, and Qlik Staige. However, IBM’s decades-long experience in enterprise-wide data management and network management will be leveraged in its new AI software tools, helping IBM to be on the short list of end-to-end AI software management providers.
The excitement around AI, which exploded in 2023, is increasing the need among enterprise customers worldwide to harness, monitor, and manage AI capabilities at the data center’s Core, the Cloud, and the Edge. The ability to monitor and manage AI across sites will be vital to enterprise customers of all sizes. They must reduce business risk while scaling up customers’ business processes as regulations governing AI use and legal compliance proliferate, growing with customers’ rapid adoption of AI across the world’s geographic regions in 2024.