A profound digital transformation is underway as High-Performance Computing (HPC) and Analytics converge to Artificial Intelligence/ Machine Learning/Deep Learning (AI/ML/DL). Across every industry, this is accelerating innovation and improving a company’s competitive position, and the quality and effectiveness of its products/services, operations and customer engagement. Consequently, with 2018 revenues of $28.1 billion, the relatively new AI market is rapidly growing at 35.6% annually[1].
As the volume, velocity and variety of data continue to explode, spending on storage systems and software just for AI initiatives is already almost $5 billion a year and expected to grow rapidly.[2] In addition, many companies are beginning to use hybrid cloud and multi-cloud computing models to knit together services to reach higher levels of productivity and scale. Today, large organizations leverage almost five clouds on average. About 84% of organizations have a strategy to use multiple clouds[3] and 56% plan to increase the use of containers[4]
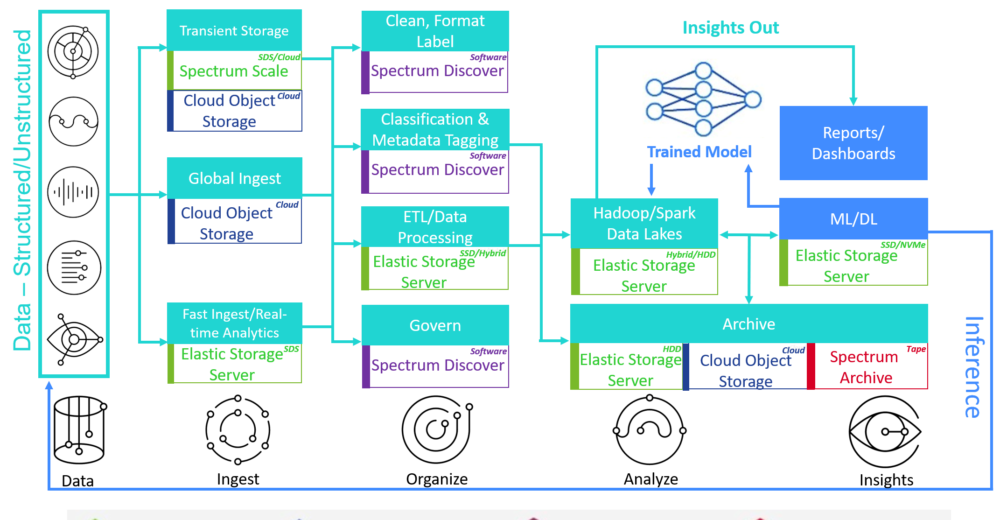
What’s needed to handle the data explosion challenges are simple, high-performance and affordable storage solutions that work on hybrid multi-cloud environments (Figure 1).
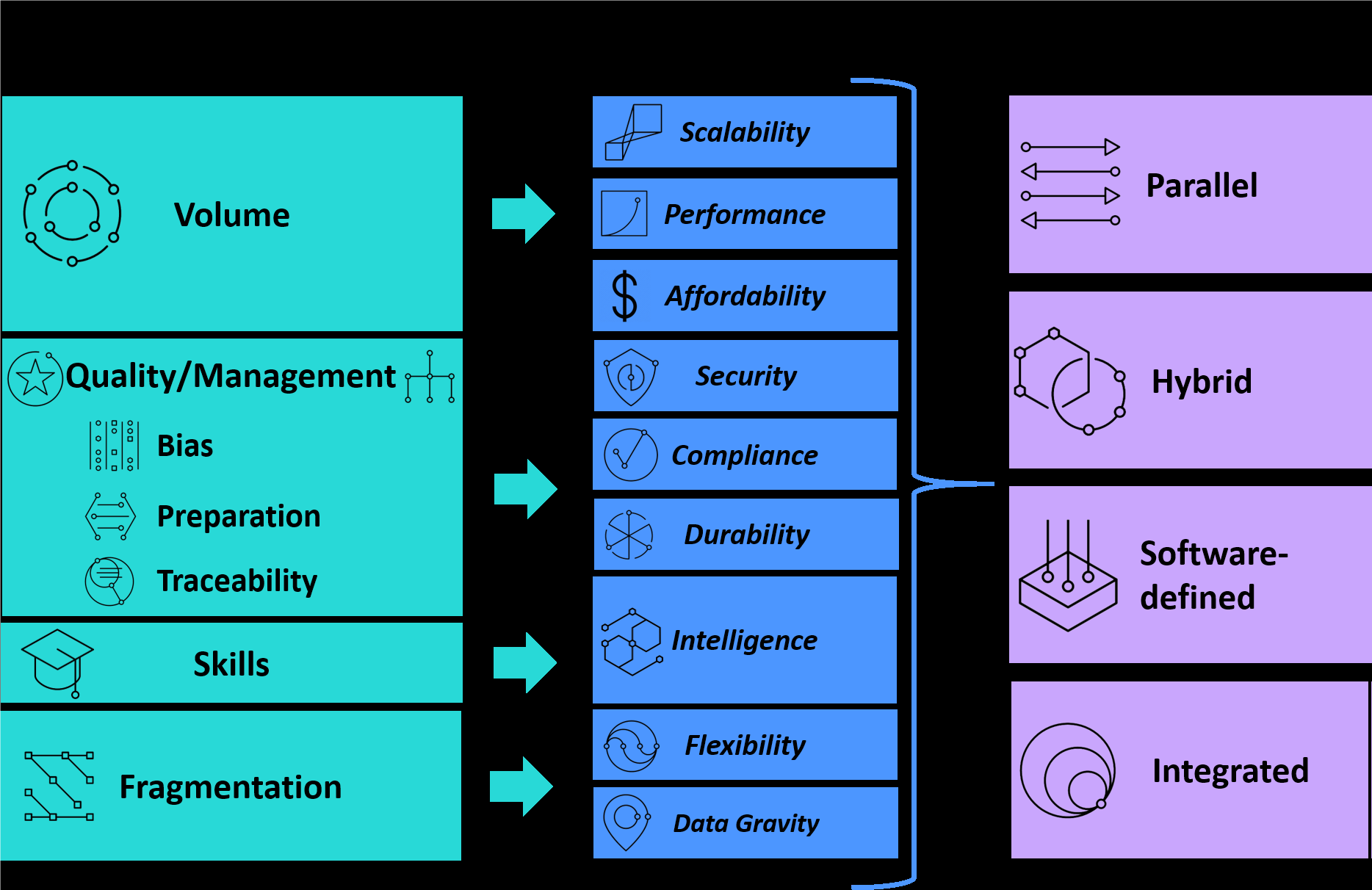
Figure 1: Data Challenges, Storage Requirements and Solutions for HPC, Analytics and AI
Key Storage Requirements
Scalable and affordable: These two attributes don’t always co-exist in enterprise storage. Historically, highly scalable systems have been more expensive on a cost/capacity basis. However, newer architectures allow computing and storage to be integrated more pervasively and cost-effectively throughout the AI workflow.
Intelligent software: This helps with the cumbersome curatorial, data cleansing tasks, and help run and monitor compute and data-intensive workloads efficiently and reliably from the edge to the core to multiple clouds. It also greatly improves the productivity of highly skilled Data Scientists, Data Engineers, Data Architects, Data Stewards and others throughout the AI workflow.
Data integration/gravity: This provides the flexibility to simplify and optimize complex data flows for performance even with data stored in multiple geographic locations and environments. Wherever possible, moving the algorithms to where the data resides can accelerate the AI workflow and eliminate expensive data movement costs especially when reusing the same data iteratively.
Storage Solutions Attributes
Parallel: As clients add more storage capacity (including Network Attached Storage – NAS), they are realizing that the operating costs (including downtime and productivity loss) of integrating, managing, securing and analyzing exploding data volumes are escalating. To reduce these costs, many clients are using high performance scalable storage with parallel file systems which can store data across multiple networked servers. These systems facilitate high-performance access through concurrent, coordinated input/output operations between clients and storage nodes across multiple sites/clouds.
Hybrid: Different data types and stages in an AI workflow have varying performance requirements. The right mix of storage systems and software is needed to meet the simultaneous needs for scalability, performance and affordability, on premises and on the cloud. A hybrid storage architecture combines file and object storage to achieve an optimal balance between performance, archiving, and data governance and protection requirements throughout the workflow.
Software-defined: It is hard to support and unify many siloed storage architectures and optimize data placement to ensure the AI workflow runs smoothly with the best performance from ingest to insights. With no dependencies in the underlying hardware, Software-defined Storage (SDS) provides a single administrative interface and a policy-based approach to aggregate and manage storage resources with data protection and scale out the system across servers. It also provides data-aware intelligence to dynamically adapt to real-time needs and orchestrate IT resources to meet critical service level agreements (SLAs) in parallel, virtual and hybrid multi-cloud environments. SDS is typically platform agnostic and supports the widest range of hardware, AI frameworks, and APIs.
Integrated: A lot of AI innovation is occurring in the cloud. So, regardless of where the data resides, on-premises storage systems with cloud integration will provide the greatest flexibility to leverage cloud-native tools. Since over 80% of clients are expected to use at least two or more public clouds[5], there will be a need for smooth and integrated data flow to/from multisite/multi-cloud environments. This requires more intelligent storage software for metadata management and integrating physically distributed, globally addressable storage systems.
IBM Spectrum Storage provides these attributes and accelerates the journey to AI from ingest to insights.
IBM Spectrum Storage and Announcements – October 27, 2020
IBM Spectrum Storage is a comprehensive SDS portfolio that helps to affordably manage and integrate all types of data in a hybrid, on-premises, and/or multi-cloud environment with parallel features that increase performance and business agility. Already proven in HPC, IBM Spectrum Storage Software comes with licensing options that provide unique differentiation and value at every stage of the AI workflow from ingest to insights
On October 27, 2020, IBM announced new capabilities and enhancements to its storage and modern data protection solutions that are designed to:
- Enrich protection for containers, and expand cloud options for modern data protection, disaster recovery, and data retention
- Expand support for container-native data access on Red Hat OpenShift
- Increase container app flexibility with object storage.
These enhancements are primarily designed to support the rapidly expanding container and Kubernetes ecosystem, including RedHat OpenShift, and to accelerate clients’ journeys to hybrid cloud. This announcement further extends an enterprise’s capabilities to fully adopt containers, Kubernetes, and Red Hat OpenShift as standards across physical, virtual and cloud platforms.
IBM announced the following new capabilities designed to advance its storage for containers offerings:
- The IBM Storage Suite for Cloud Paks is designed to expand support for container-native data access on OpenShift. This suite aims to provide more flexibility for continuous integration and continuous delivery (CI/CD) teams who often need file, object, and block as software-defined storage. This is an enhancement with new Spectrum Scale capabilities.
- Scheduled to be released in 4Q 2020, IBM Spectrum Scale,a leading filesystem for HPC and AI, adds a fully containerized client and run-time operators to provide access to an IBM Spectrum Scale data lake, which could be IBM Elastic Storage systems, or an SDS deployment. In addition, IBM Cloud Object Storage adds support for the open source s3fs file to object storage interface bundled with Red Hat OpenShift
- For clients who are evaluating container support in their existing infrastructure, IBM FlashSystem provides low latency, high performance, and high-availability storage for physical, virtual, or container workloads with broad CSI support. The latest release in 4Q 2020 includes updated Ansible scripts for rapid deployment, enhanced support for storage-class memory, and improvements in snapshot and data efficiency
- IBM Storage has outlined plans for adding integrated storage management in a fully container-native software-defined solution. This solution will be managed by the Kubernetes administrator, and is designed to provide the performance and capacity scalability demanded by AI and ML workloads in a Red Hat OpenShift environment.
- IBM intends to enhance IBM Spectrum Protect Plus, to protect Red Hat OpenShift environments in 4Q 2020. Enhancements include ease of deployment with the ability to deploy IBM Spectrum Protect Plus server as a container using a certified Red Hat OpenShift operator, the ability to protect metadata which provides the ability to recover applications, namespaces, and clusters to a different location, and expanded container-native and container-ready storage support. IBM is also announced the availability of a beta of IBM Spectrum Protect Plus on Microsoft Azure Marketplace
- IBM announced expanded hybrid cloud support for IBM Spectrum Protect, new Gen7 b-type SAN switches and directorswith new IBM SANnav management software, both available in 4Q 2020, and plans for products based on new LTO 9 tape technology designed to enhance cyber resilience, expected in 1H 2021.
Conclusions
As HPC and Analytics grow and converge, clients can continue to leverage these new IBM storage capabilities to overcome the many challenges with deploying and scaling AI across their enterprise. These simple storage solutions – on-premises or on hybrid multi-clouds can accelerate their AI journey from ingest to insights.
[1] https://www.idc.com/getdoc.jsp?containerId=US45334719
[2] http://www.ibm.com/downloads/cas/DRRDZBL2
[3] RightScale® STATE OF THE CLOUD REPORT 2019 from Flexera™
[4]https://www.redhat.com/cms/managed-files/rh-enterprise-open-source-report-detail-f21756-202002-en.pdf
[5] https://www.gartner.com/smarterwithgartner/why-organizations-choose-a-multicloud-strategy/









Very comprehensive assessment Ravi!